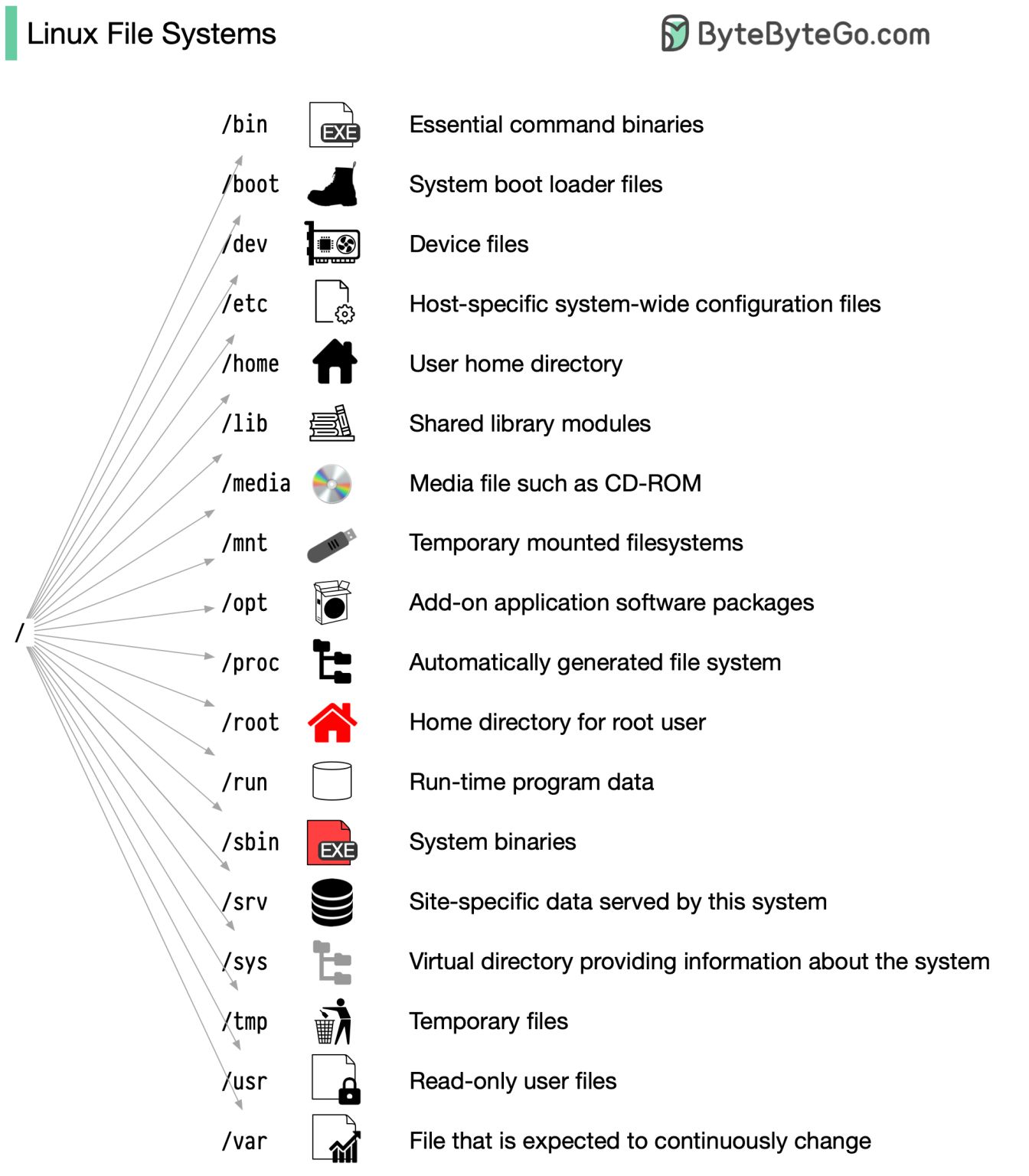
Linux File System
Commonds
df 查看磁盘占用情况
df -h 以易读格式显示
du 查看文件占用磁盘大小
du -sh 目录名
du -sh * | sort -nr| head #查看文件大小并排序
top 查看CPU占用率
top -u 用户名 查看某用户的cpu使用情况
free 查看内存使用
free -m 以MB为单位显示内存使用情况
sort 排序
-f 忽略大小写
-b 忽略最前面的空格符
-M 以月份名字排序
-n 以纯数字排序
-r 反向排序
-u 重复数据只显示其中一行
-t 分隔符,默认 tab
-k 以某个分隔区间排序
cat /etc/passwd | sort -t ':' -k 3 -n
example:
sort test.txt | uniq -d # 统计重复行
chmod 修改权限
chmod -R 777 /test 更改test目录下所有文件权限为777
chown 更改所有者
chown yuqiuwen test.sh 修改test.sh文件所有者为yuqiuwen
uname 显示系统信息
uname -a 显示系统详细信息
tar 解压缩
tar -zxvf 解压文件
tar -cvf 打包文件
查看cpu配置
cat /proc/cpuinfo
grep
-a 将binary文件以text文件的方式搜寻数据
-c 计算找到所搜寻字符串的次数
-i 忽略大小写
-n 输出行号
-v 反向选择
--color=auto 关键词部分加上颜色
正则匹配
^ 行的开始 如:'^grep'匹配所有以grep开头的行。
$ 行的结束 如:'grep$'匹配所有以grep结尾的行。
. 匹配一个非换行符的字符 如:'gr.p'匹配gr后接一个任意字符,然后是p。
* 匹配零个或多个先前字符 如:'*grep'匹配所有一个或多个空格后紧跟grep的行。
.* 一起用代表任意字符。
\? 匹配其前面的字符0次或者1次;
\+ 匹配其前面的字符至少1次;
[] 匹配一个指定范围内的字符,如'[Gg]rep'匹配Grep和grep。
[^] 匹配一个不在指定范围内的字符,如:'[^A-FH-Z]rep'匹配不包含A-R和T-Z的一个字母开头,紧跟rep的行。
\(..\) 标记匹配字符,如'\(love\)',love被标记为1。
\< 锚定单词的开始,如:'\<grep'匹配包含以grep开头的单词的行。
\> 锚定单词的结束,如'grep\>'匹配包含以grep结尾的单词的行。
x\{m\} 重复字符x,m次,如:'0\{5\}'匹配包含5个o的行。
x\{m,\} 重复字符x,至少m次,如:'o\{5,\}'匹配至少有5个o的行。
x\{m,n\} 重复字符x,至少m次,不多于n次,如:'o\{5,10\}'匹配5--10个o的行。
\w 匹配文字和数字字符,也就是[A-Za-z0-9],如:'G\w*p'匹配以G后跟零个或多个文字或数字字符,然后是p。
\W \w的反置形式,匹配一个或多个非单词字符,如点号句号等。
\b 单词锁定符,如: '\bgrep\b'只匹配grep。
awk
必须外层用单引号,内层双引号
NF 分割后当前行一共有多少字段
NR 行数
FS 字段分隔符,默认空格
FS 字段分隔符(默认是任何空格)
OFS 输出字段分隔符(默认值是一个空格)
RS 记录分隔符(默认是一个换行符)
ORS 输出记录分隔符(默认值是一个换行符)
ARGC 命令行参数的数目
ARGV 包含命令行参数的数组
-F 指定分割符,默认空格
-f 从脚本文件中读取
-v 赋值一个用户定义变量,将外部变量传递给awk
awk [option] pattern {action} file
awk 'END{print NR}' test.log # 统计文件行数
awk 'NR==3,NR==6{print NR,$0}' test.log # 查看第3到第6行,$0代表整行,NR输出行号
awk '{print $1,$(NF-1)}' test.log # 查看第一列和倒数第二列
ifconfig eth0 | awk 'NR==2{print $2}' # 取ifconfig eth0中第二行第二列的ip
awk -F ":" -v OFS="\t" 'NR==3,NR==6{print $1,$NF}' test.log # 指定输出分隔符
awk -v ORS=" " 'NR==3,NR==6{print NR,$0}' test.log # 以空格作为换行标志
awk 'BEGIN{print ARGV[0],ARGV[1]}' test.log # 访问数组中的第1、2个值
awk -v myname="哈哈哈" 'BEGIN{print myname}'
sed
health_center.log日志文件如下:

-n 仅显示处理后的结果
-e 以选项中的指定的script来处理输入的文本文件
-i 直接编辑源文件
p 打印
d 删除
a 在当前行下面插入文本。
i 在当前行上面插入文本。
s 替换指定字符
g 获得内存缓冲区的内容,并替代当前模板块中的文本。
// 模式匹配
sed -n '1,6p' health_center.log # 统计1到6行的文本
sed -n '1,+6p' health_center.log # 输出第1行和之后的6行(共7行)
sed -n '/ERROR/p' health_center.log # 输出包含ERROR的行
sed "/INFO/d" test.log # 删除含有INFO的行(不会操作源文件)
sed -i "/INFO/d" test.log # 删除含有INFO的行(直接操作源文件)
sed '10001,$d' test.log -i # 删除从10001行到末尾的行
sed "s/WARNING/ERROR/g" test.log -i # 将WARNING替换为ERROR
sed -e "s/ERROR/WARNING/g" -e "s/2022-05-28/2023-05-28/g" test.log -i # 替换多个
sed "1a 123456" test.log -i # 在第1行的下面添加一行123456
sed "1i abcde" test.log -i # 在第1行的前面添加一行abcde
sed "1a tomorrow will be fine.\n okay okay" test.log -i # \n表示在第1行的下面添加多行文本
sed 'a ------------' test.log # 在每一行下面添加------------字符
### 文本如下,获取第二行中的ip 172.26.25.254
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.26.25.254 netmask 255.255.192.0 broadcast 172.26.63.255
ether 00:16:3e:15:c5:19 txqueuelen 1000 (Ethernet)
RX packets 1338810002 bytes 88450660493 (82.3 GiB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 21251292571 bytes 1463867614512 (1.3 TiB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
# 结合正则表达式,2s中的2代表第二行
ifconfig eth0 | sed -e "2s/^.*inet //" -e "2s/net.*$//p" -n
wc 统计字符
-l 行
-w 英文字
-m 字符
ps 查看进程
ps -ef | grep python 显示系统中的python进程
kill 杀死进程
# grep -v grep 过滤掉grep本身所占进程
# awk '{print $2}' 提取找到的进程行记录中第二列的参数,也就是python的进�程号
# xargs kill -9 把前面的参数都传递给后面的命令 kill -9
ps -ef | grep python | grep -v grep | awk '{print $2}' | xargs kill -9
netstat 查看网络端口信息
netstat -ntlp
ss -nltp
curl 获取网址信息
curl www.baidu.com 获取该网址的文本信息
curl -i www.baidu.com 获取该网址的文本信息以及协议头部信息
curl -x www.baidu.com 使用代理获取网页文本信息
curl -X POST --header "Content-Type:application/json" --data '{}' www.baidu.com/getAllUserInfo 使用post模拟json格式请求接口
tail 根据位置输出文件内容
tail -n 10 error.log 查看最新10行
tail -n +20 error.log 从第20行开始输出
tail -c 10 error.log 输出最后10个字符
tail -c +10 error.log 从第10个字符开始输出
tail -f error.log 持续输出指定文件最新10行
sz rz 上传下载
sz filename 下载文件到本地
rz filename 上传文件到服务器
sftp 传输文件
sftp root@10.2.21.21
sftp> get /aa/bb/cc.txt /home/ # 将21机器上的cc.txt文件下载到home目录
sftp> put /aa/bb/cc.txt /home/ # 将cc.txt文件上传到21机器上的home目录
sftp> ls
sftp> pwd //查询当前工作目录
rsync传输文件
rsync -av -e ssh --exclude 'exclude_path绝对路径' 本地路径 远程路径
test 判断文件是否存在
test -e file.txt && echo 11 || echo 10 #存在则输出11
环境变量
~/.bashrc
生效时间:使用相同的用户打开新的终端时生效,或者手动source ~/.bashrc生效
生效期限:永久有效
生效范围:仅对当前用户有效
如果有后续的环境变量加载文件覆盖了PATH定义,则可能不生效
会在每次运行Shell脚本的时候读取一次
~/.bash_profile
生效时间:使用相同的用户打开新的终端时生效,或者手动source ~/.bash_profile生效
生效期限:永久有效
生效范围:仅对当前用户有效
如果没有~/.bash_profile文件,则可�以编辑~/.profile文件或者新建一个
只在用户登录的时候读取一次
/etc/bashrc /etc/profile(bash_profile)
生效时间:新开终端生效,或者手动source /etc/bashrc生效
生效期限:永久有效
生效范围:对所有用户有效
/etc/environment
生效时间:新开终端生效,或者手动source /etc/environment生效
生效期限:永久有效
生效范围:对所有用户有效
环境变量加载顺序(系统级->用户级):
- /etc/environment
- /etc/profile
- ~/.bash_profile
Linux环境变量配置全攻略 - 悠悠i - 博客园 (cnblogs.com)
shell

批量替换文件名
# 替换aa_bb_finished.jpg为aa_bb.jpg
for file in ls *fin*jpg;do mv $file `echo ${file//_finished/}`;done